
의사결정트리 (Decision Tree) 정리
Updated:
정보함수
정보함수는 정보의 가치를 반환하는 함수로 발생확률이 낮을 수록 반환값이 커지고 반대인 경우 작아지게 된다.
정보함수 수식은 다음과 같다.
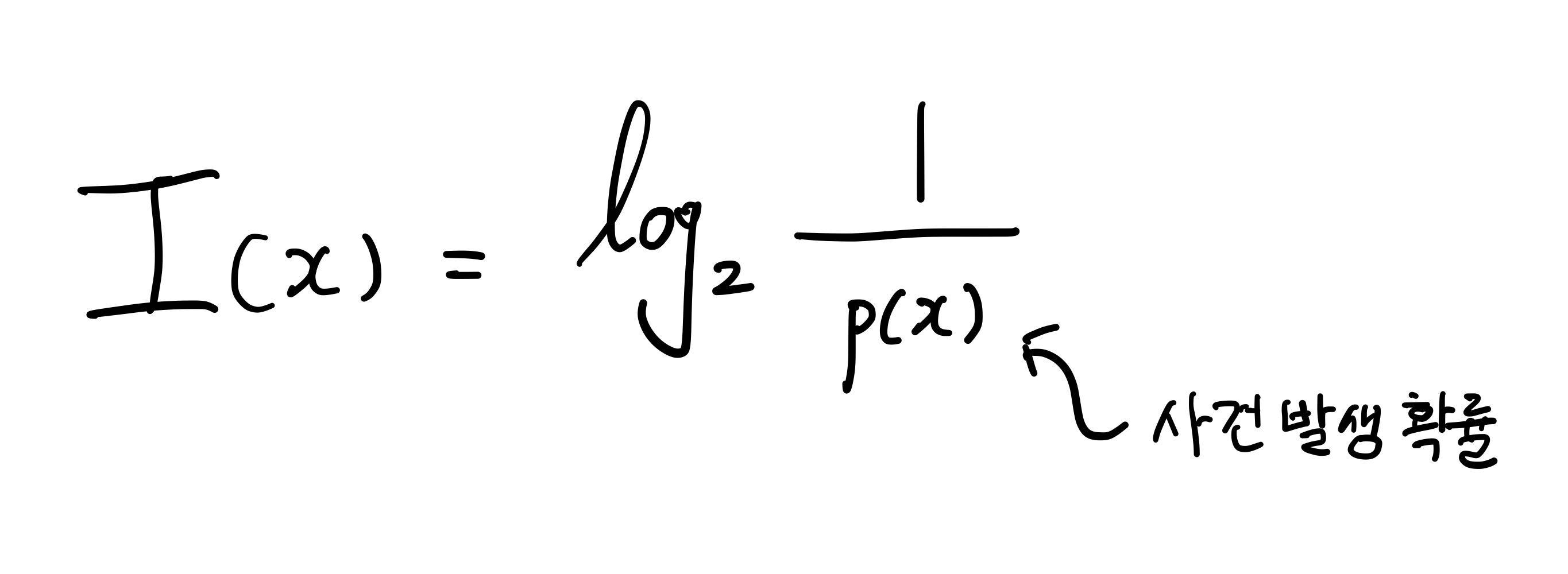
정보함수를 간단히 그려보면 아래와 같은 감소함수가 그려진다.
.jpg)
쉽게 생각하여 별로 정보가 없는 사건은 희귀하기 때문에(?) 그 가치를 높게 평가하고 정보가 많은 사건은 모두가 다 알기 때문에(?) 가치가 낮다고 정리할 수 있을 것 같다.
엔트로피
엔트로피는 무질서를 정량화한 값이다. 엔트로피가 높을수록 무질서도가 높기 때문에 정보를 얻기 어렵다. 반대로 엔트로피가 낮으면 무질서도가 낮아 정보를 얻기 쉽다. 즉 분류를 위해서는 집단(클래스)간 정보를 얻고 분류해야 하므로 엔트로피를 낮게 하는 방향으로 학습이 진행되어야한다.
.jpg)
위 그림은 어떤 영역 A의 데이터를 나타낸 것이다. 빨간색의 1번 클래스와 파란색의 2번 클래스의 데이터가 각각 8개, 5개씩 존재한다. 위 영역A의 엔트로피를 구해보자.
.jpg)
정보획득량
정보획득량은 이전 엔트로피에서 분류 후 엔트로피의 차이를 의미한다. 엔트로피는 위에서 무질서도를 정량화한 값이라 설명했다. 분류 후 엔트로피가 감소하게 되면 무질서도가 감소했단 의미이며, 이는 정보(혹은 특징)을 그만큼 얻을 수 있다는 의미이다.
위 영역 A를 A1과 A2영역으로 나누었다.
.jpg)
그 후 각 영역에 대해 엔트로피를 구해보면
.jpg)
이제 영역 분류 전 A와 분류 후 A’의 엔트로피 변화량을 계산하면
.jpg)
실제 계산을 끝까지 하진 않았지만 만약 엔트로피가 분류 후 감소하게 되었다면 의사결정트리는 분류를 하는 것이 낫다는 판단 후 분기를 실행한다.
재귀적 분기
- 분류 데이터를 생성한다. (ex 나이, 키, 성별 3개의 특징점을 가진 100개의 데이터)
- 한 특징점에 대하여 정렬을 한다. (나이순으로 정렬)
- 첫 데이터(0번째 데이터)와 나머지 99개의 데이터를 분류하여 분류 이전과 이후의 엔트로피를 계산한다 (= 정보획득량을 계산).
- 0~1번째 데이터와 나머지 98개의 데이터에 대하여 3번 과정을 반복한다.(0번 데이터와 나머지 1~99번 데이터로 분류 후 엔트로피 감소량 계산, 0번+1번 데이터와 2~99데이터로 다시 계산…이를 반복)
- 4번을 끝까지 반복한다(총 99번 반복)
- 가장 정보획득량(엔트로피 감소량)이 큰 경우를 찾아 분류한다.
- 2~6의 과정을 각 특징점 별로 진행한다. (나이순으로 했으니 키 순으로 정렬 후 반복, 다시 성별로 정렬 후 반복)
위 과정은 각 특징점 별로 데이터의 수-1 만큼 반복되기 때문에 총 연산 수는 F * (N-1)이다 (F = 특징점 수, N = 데이터 수)
가지치기
위 재귀적 분기를 하게 되면 데이터가 여러 갈래로 나뉘게 된다. 하지만 너무 많은 분기가 발생하면 데이터에 과적합되는 문제가 발생할 수 있기 때문에 분기 횟수를 적절하게 정하는 것이 중요하다.
가지치기는 사전과 사후 두 종류가 있다. 사전 가지치기의 경우 미리 트리의 최대 가지 수, 노드의 최소 데이터 수 등의 하이퍼파라미터를 설정하여 학습이 진행되다가 조건을 만족하지 않는 경우 학습이 종료되는 방법이다. 반면 사후 가지치기는 트리가 완성 된 이후, 말단 노드 혹은 터미널 노드를 결합하면서 적절한 분기 수를 갖도록 하는 방법이다.
의사결정트리는 다음의 수식의 반환값을 최소로 하게끔 학습이 진행된다.
- 트리의 비용 복잡도 = 오분류율 * a * 터미널 노드 수
DecisionTreeClassifier(random_state)에 난수가 왜 필요할까?
Q : what does “random_state” do in DecisionTreeClassifier ?
의사결정트리가 분기를 할 떄는 다음의 룰을 따른다. 각 feature별로 최대 정보획득량(엔트로피의 감소량)을 구하여 이들 중 가장 큰 값을 갖는 feature에 대해 분기를 진행함. 그리고 이를 반복한다.
코드를 작성하는데 scikit-learn의 DecisionTreeClassifier에 랜덤 시드가 들어가는데 이게 어디서 쓰이는지 몰라서 한참을 여러 사람들과 이야기하였다. 사이킷런공식문서 를 보면
The features are always randomly permuted at each split, even if splitter is set to “best”. When max_features < n_features, the algorithm will select max_features at random at each split before finding the best split among them.
이라고 나와있다. 이 때 max_feature은 우리가 분기를 진행할 때 고려할 feature의 수를 의미한다(함수 호출 시 인자로 넣는 값, default=none). n_features는 데이터의 총 feature 수를 의미하는 것 같다.
해석하자면 스플리터 인자가 best로 설정되어 있어도, random_state가 설정되면 각 분기마다 랜덤하게 고려할 feature를 고른다는 것이다. 이 때, 고려할 feature의 수는 max_features가 된다.
일반적인 의사결정트리는 각 분기마다 features 중 가장 엔트로피 감소량이 높은 것을 기준으로 분기하게 된다. 하지만 이 결정이 최적의 분류를 보장하지는 않기 때문에 전체 features 중 max_features 만큼의 feature를 골라서, 그 중에서 감소량이 높은 feature를 고르게 되는 것이다.
만약 max_features = n_features인 경우는 어떻게 될까? 전체 4개의 feature중 랜덤하게 4개를 뽑았다 한들, 항상 동일한 feature가 선택될 것이다. 따라서 그 결과는 항상 같게 나올 것이다. 하지만 그렇지 않은 경우가 있는데 이 경우는 일부 분기에서 엔트로피 감소량이 같은 features가 나타나면 랜덤하게 선택해서 분기를 해야 하기 때문에 발생하게 된다.
깔끔하게 해결되지 않아서 스스로 이해한 바를 정리한 글입니다. 오류나 다른 의견이 있으시면 댓글로 달아주세요:)
Leave a comment